RSS 的全称是 Really Simply Syndication,简易信息聚合。顾名思义就是将各个地方的信息汇聚起来,放在一个地方阅读。对这个词你可能会觉得很陌生,不过没关系这只是计算机领域的一个专有名词,不认识也没关系。它的用处是什么?简单来讲就是把各个提供订阅服务的网站订阅起来,有内容更新的时候会自动告诉你,从此就不用手动打开收藏夹一个个点击去看了。不得不说,尤其适用于订阅一月更新一两次的本博客。
本软文介绍的是一个 RSS 阅读网站,NewsZeit(https://www.newszeit.com/)。关于它和 NewsBlur 的渊源就不说了,花几分钟注册以后,整个网站打开看起来是这样子的:
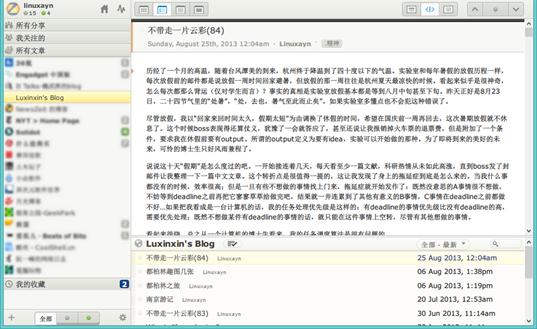
不好意思又拿自己的博客作为示例了,是不是看起来就很专业的样子?左边是订阅的站点列表,除了我的博客外其他都给模糊处理了;右边上方是文章的内容,下方是该站点的文章列表。其实使用起来很简单,就像用一般网站那样该怎么用就怎么用好了——要是把软件用坏了我会很郁闷,但是把网站给用坏了的话我会很自豪,原来我也有做黑客的天赋。
值得小心的是,很多地方都可以用右键点击,当你想找某些功能死活找不到的话,不如试试点击右键。这也是 NewsZeit 的缺点之一:为了界面的美观而牺牲了可用性。
我推荐的理由如下:
首先,有 Android 和 IOS 客户端,因此不仅可以在电脑上看,也可以在手机上随时阅读订阅的内容。不过有点值得注意的是如果使用流量上网的话,客户端是不会像 UC 浏览器那样对图片进行压缩的,小心你的流量。
其次,足够简单,不需要学习即可上手,作为一个 RSS 阅读器实在是没有什么可挑剔的了。例如订阅我这个博客的话,点击右下角的”+”,输入我博客的域名,再点击” 添加站点” 就可以了:
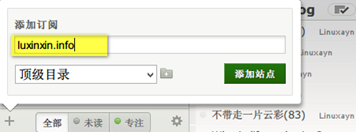
当然这是因为我的博客没人看,如果是订阅一些大站的话,只要输入几个字母就可以找到它们了。
第三,服务器似乎是在国外的,阅读全程使用 https 进行加密,因此可以看一些心智成熟的人才能看的内容哦(别想歪了,我说的是 CNN,New York Times 之类的网站….)
第四,它看起来很智能,可以根据用户的喜好来推荐优先阅读的文章(在 NewsZeit 里面所谓的专注模式)。作为一个研究人工智能的博士生,这点特性令我很兴奋,尽管我说的还是” 看起来” 。就网站上介绍的来说,它支持根据” 网站”,” 作者” 以及” 标签” 对用户喜爱的内容进行智能训练。看它的依赖库就知道了,需要使用 Numpy 和 Scipy 那必然是有些数值运算在里面的,有空 checkout 代码出来看看它的实现机制是用了什么方法。
最后一个推荐理由是,写完本篇博客可以给我增加六个月的高级会员使用时间。注册完之后是免费用户,免费用户也没什么大缺陷,好像是订阅的网站数目不能超过 40 个?不能使用搜索功能,以及不能使用文件夹”River of news” 功能。厚道的网站站长正在推广 NewsZeit,不用写博客去新浪微博转发一下某条微博也可以获得三个月的高级用户使用时间。
作为普通用户看到这里基本就可以止住了,欢迎订阅我的博客!下面是作为一名科研工作者对 NewsZeit 的 YY:
首先,更好地支持” 智能训练” 。目前的训练只基于” 网站”,” 作者” 和” 标签”,而其中标签是文章的作者主动标上去的,要是能基于内容来推荐文章那就更好了,甚至还可以做到用户不用订阅站点也看到自己喜欢看到的内容。不过这就偏向于像内容推荐网站了,似乎和目前的定位不太一致。
其次,添加基于关键词的订阅。目前的订阅只是基于站点的订阅,也就是说网站提供给你什么你就看什么。比如说,最近关于叙利亚的生化武器事件很火,要是能订阅” 叙利亚” 或者”Syria” 作为我的内容需求,当 NY Times 更新了最新的叙利亚的消息我马上就能收到关于叙利亚的最新报道,那该多好。就实现上来讲,由于没看过 NewsZeit 的代码,不好说在现有的基础上容不容易改,不过基本思路就是一个倒排表索引吧。
话说回来,其实要是咱实验室要是也有个 NewsZeit 就好了,可以很容易地积累大量的真实实验数据,里面会面临着很多有趣的问题,而且有人使用就是对科研的最大激励。实验室最大的问题就是没有一个现实的系统,可惜就是没人推动去做这个事情,因为很花精力而且需要长期坚持。